ASCII,Latin1,GBK,Utf8,... 字符集编码,乍一听似乎是一个简单的东西,但它却隐藏着丰富的历史故事(乱)和复杂的技术细节(杂)..., 不妨抛开细节和完整性,简单写写
从Python开始?
都2025年了,尽管 C++引入了一个又一个字符类型 ,但即便是在最简单的UTF-8编码上,C++仍在苦苦挣扎。
所以我们还是从Python3开始吧,毕竟和C/C++,甚至是Python2相比,它非常简单,不是么?
初识 Python 内置编码
不考虑别名的话,Python也支持将近百种编码,可以列个表格(本文重点关注标红和标绿的部分):
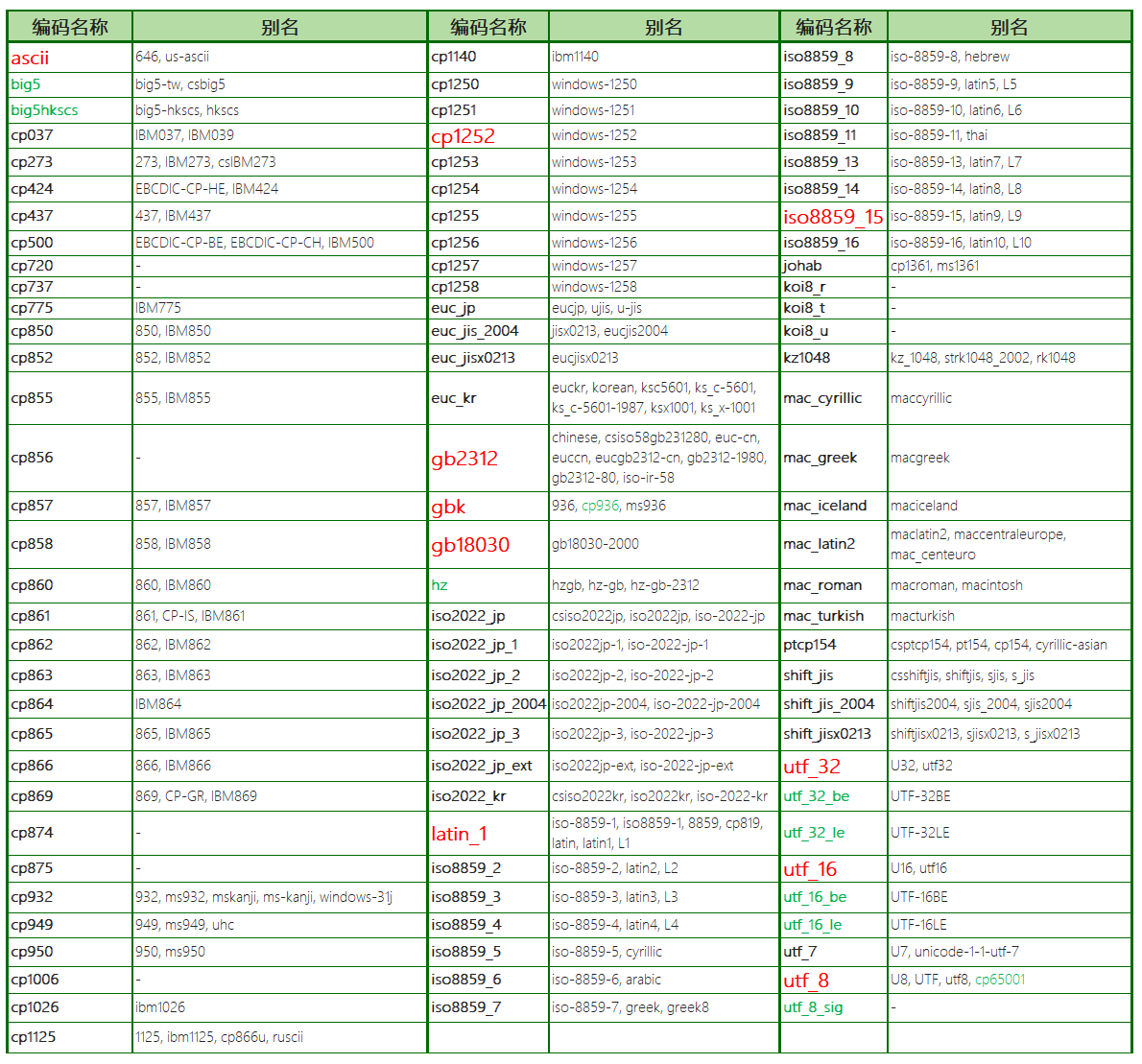
尽管看起来还是很杂,但上面表格已经做了很多简化。比如,表中ascii只列出2个别名,其实在Python下,单单一个ascii,有如下一堆别名:
646ansi_x3.4_1968ansi_x3.4_1986ansi_x3_4_1968cp367csasciiibm367iso646_usiso_646.irv_1991iso_ir_6usus_ascii
获取编码名
要获得python内置的完整的编码列表,可通过如下python代码输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
太多了,怎么看?
按时间先后看看,挑几个关键节点看看??
EBCDIC 编码(8bit),1963
在 ASCII 之前,已经存在 EBCDIC 编码,但是EBCDIC 是 IBM 的专有编码,不是开放标准。
- BCD:全称 Binary Coded Decimal(二进制编码十进制),起源于1940年代
- EBCDIC:全称 Extended Binary Coded Decimal Interchange Code(扩展二进制编码十进制交换码),1963年,IBM推出基于BCD的扩展,主要用于IBM大型机。
EBCDIC 有超过186种变体(代码页)。前面表格中出现的,以下编码,属于 EBCDIC 的变种:
- CP037
- CP424
- CP500
- CP875
- CP1026
- CP1140
ASCII 标准诞生(7bit),1967
ASCII,发音 /ˈæskiː/
随着个人计算机(PC)的普及,ASCII 成为跨平台的通用编码。而由于 ASCII 与 EBCDIC 不兼容,ASCII 的普及也推动了 EBCDIC 的边缘化。
- ASCII:全称 American Standard Code for Information Interchange,1967年,由 ANSI(美国国家标准协会),作为行业标准发布。
不过 ASCII ,只有7bit,容量实在太小了,只能照顾到美国,连英国可能都不舒服(英镑符号 £ 在哪里?)
ASCII 扩展:商业公司
ASCII只使用7bit,把高位置一,还可以多存储128个字符。多出来的这部分,到底存法语字符呢,存葡萄牙语字符呢,还是阿拉伯语字符呢?
分而治之,分别用不同的代码页(code page)不就得了。于是
IBMxxx 扩展
IBM 整出了下面一堆和ASCII兼容的东西:
- cp437 / IBM437
- cp850 / IBM850
- cp852 / IBM852
- cp855 / IBM855
- cp857 / IBM857
- cp858 / IBM858
- cp860 / IBM860
- cp861 / IBM861
- cp862 / IBM862
- cp863 / IBM863
- cp864 / IBM864
- cp865 / IBM865
- cp866 / IBM866
- cp869 / IBM869
- ...
Apple 扩展
苹果公司闲不住,有如下东西:
- mac_cyrillic
- mac_greek
- mac_iceland
- mac_latin2
- mac_roman
- mac_turkish
ASCII 扩展:ISO 8859 系列标准
在 1987 年,国际标准化组织(ISO)发布了一组针对 8 位 ASCII 扩展的标准,即 ISO 8859 系列。
注意:与其他编码相比,ISO 8859 将 8016 到 9F16(十六进制)这 32 个字符位置保留为控制字符。
该系列中,最流行的是
- ISO 8859-1(ISO Latin 1),它包含了大多数常见西欧语言字符。
- ISO 8859-15(ISO Latin 9),是 Latin1 的改进版,使用欧元符号 € 等取代了Latin 1中的一些不常用的字符。
一共15个标准:
- ISO 8859-1 to 11
- ISO 8859-13 to 16
其中:ISO 8859-12 从未被正式分配,直接被跳过了。
ISO-8859-1 扩展:Windows-1252
Windows-1252 也被称为 CP1252、Windows Latin 1 甚至是 ANSI。它支持大部分的 西欧语言,包括英语、法语、德语、西班牙语、意大利语、葡萄牙语、荷兰语、丹麦语、瑞典语、挪威语等。
尽管和 Latin-1(ISO 8859-1)非常相似,但是并不相同,它在ISO 8859 的保留区里面,塞了很多其他字符,比如 欧元符号 €。
曾经的辉煌:
- Windows-1252 是Windows默认的编码之一,特别是在早期的 Microsoft Office 文档(如 Word 和 Excel)中。
- 在 HTML 和网页开发中,Windows-1252 曾被广泛使用,特别是在西欧语言网站中。
- 在未指定编码的情况下,许多早期的浏览器(如 Internet Explorer)会默认使用 Windows-1252。
HTML5 的妥协:将 ISO-8859-1 视为 Windows-1252
在 HTML5 标准中,如果在网页中声明了字符编码为 ISO-8859-1,浏览器会将其解释为 Windows-1252,而不是严格意义上的 ISO 8859-1。
这种行为是为了保证向后兼容,因为早期大量网页实际使用的是 Windows-1252,而不是 ISO 8859-1。
Windows-125x 字符集
Microsoft 定义了一系列 Windows-125x 字符集,用于支持不同语言和地区的文本编码。这些字符集都是基于 单字节编码,每个字符占用 1 个字节,最多支持 256 个字符。
这一系列可以和 ISO-8859 系列进行对应。二者的根本区别和 前面 ISO-8859-1 与 Windows 1252 的区别一样。
| 特性 | Windows-125x | ISO-8859 系列 |
|---|---|---|
| 范围 | 0x00-0xFF | 0x00-0xFF |
| 差异 | 0x80-0x9F 区域是可打印字符 | 0x80-0x9F 区域是控制字符 |
| 使用场景 | Windows 系统 | 早期的 UNIX 和网络协议 |
中文编码:GB2312、GBK、GB18030
ISO-8859 基本解决了除了中国、日本、韩国之外,其他国家的编码问题。但是一个8位字节,铁定无法解决中日韩字符编码
GB2312:区位码
GB2312 是中国国家标准化管理委员会于 1980 年发布的一种字符集标准,全称是 《信息交换用汉字编码字符集·基本集》。它是中国最早的用于计算机处理简体汉字的编码标准之一,主要用于简体中文的显示和处理。
- GB2312 将所有字符划分为 94 个区,每区包含 94 个字符。
- 区号和位号的范围均为 01-94。
- 每个字符的位置由 区号 和 位号 唯一确定。
为了与 ASCII 兼容:用于计算机编码时,区位码会加上一个偏移量 0xA0 转化为机内码。
GBK
1993年,Unicode 1.1 标准发布。
同年,GBK开始定义。
GBK(汉字内码扩展规范)是对 GB2312 的扩展,兼容 GB2312 的所有字符,同时新增了 21003 个汉字(对应于Unicode 1.1 引入的汉字),包括繁体字、更多生僻字和少数民族语言字符。
微软的代码页 CP936 基本可以认为对应 GBK。
GB18030
GB18030 是中国国家标准,支持所有 Unicode 字符,是中文字符编码的最新标准。
GB2312 和 GBK 都是 GB18030 的子集。
中文编码:Big5、Big5-HKSCS
Big5 是一种用于繁体中文字符的编码标准,最早由台湾的五家厂商(因此得名 Big5)在 1984 年共同制定。它是繁体中文计算机系统中最广泛使用的字符集之一,尤其在台湾和香港地区应用广泛。
作为一种双字节编码方案,Big5 设计上与 GB2312 类似,但它专注于繁体中文的字符集。
初版 Big5 的字符集有限,无法覆盖所有繁体中文字符以及其他扩展需求。后续版本增加了一些扩展字符集,例如:
- Big5+:新增字符以支持更多的生僻字和罕见字符。
- Big5-HKSCS(香港增补字符集):为香港特别行政区设计的扩展版本,增加了约 5000 个字符,用于处理香港地区的独特用字。
ISO-2022-CN
前述各个字符集之间缺乏统一性,导致跨语言和跨系统的文本交换变得困难。因此,ISO 2022 的诞生旨在提供一种灵活的机制,允许在同一数据流中动态切换字符集,以支持多语言环境。
- 1971 年:首次发布 ISO 2022,成为早期字符编码标准的基础,用于多语言文本支持。
- 1986 年:进行了修订,逐步完善了字符集切换的机制,支持更多的字符集。
- 1994 年:被重新编号为 ISO/IEC 2022,并纳入国际电工委员会(IEC)的标准体系。
下面这些东西,韩国和日本(曾经)用的比较多:
- ISO-2022-CN,
- ISO-2022-CN-EXT,
- ISO-2022-JP,
- ISO-2022-JP-1,
- ISO-2022-JP-2
- ISO-2022-KR
基本被unicode取代了
EUC(Extended Unix Code)
EUC(Extended Unix Code,扩展 UNIX 编码) 是一种多字节字符编码,用于在 UNIX 和类 UNIX 系统中表示多种东亚语言字符集(如日文、韩文和中文)。EUC 是基于 ISO 2022 编码标准的扩展,能够在同一编码中支持多种字符集,并且保持对 ASCII 的兼容性。
这个编码日本和韩国还在用,在前面python的表格中,可以看到下面4个:
euc_jpeuc_jis_2004euc_jisx0213euc_kr
在中国,euc_cn 需要配合 GB2312 使用,但是 GB2312 已经被 GBK 和 GB18030 取代。
Unicode
小结一下:
- ASCII:用于英语和西方语言的 7 位编码。
- ISO 8859 系列:分为多个版本,用于不同的西方语言。
- GB2312:用于简体中文的字符集。
- Big5:用于繁体中文的字符集。
- ISO/IEC 2022:没能很好解决这个问题
可以发现存在致命问题:
- 不兼容性:不同编码系统之间无法互相解读。
- 字符冲突:同一个字节值在不同编码中可能代表完全不同的字符。
- 缺乏全球化支持:无法同时支持多种语言文字。
如何解决?
Unicode 与 UCS
为了统一全球字符编码,早期出现了两个独立的组织:
- Unicode 联盟(Unicode Consortium) 于 1987 年成立。1991 年发布Unicode 1.0,支持固定长度的 16 位编码,能够容纳 65,536 个字符。
- UCS(通用字符集,Universal Character Set)由 ISO/IEC 10646 国际标准定义的。第一个版本(ISO 10646-1:1993)发布于 1993 年,定义了一个更大的编码空间(31 位),远远超过 Unicode 的初始设计范围。
从 Unicode 2.0 起(1996 年),Unicode 和 ISO/IEC 10646 的编码点完全同步。Unicode 2.0 版本扩展到 21 位范围(0x000000–0x10FFFF),并引入了补充平面,覆盖了更多的字符。
UCS-2、UCS-4、UTF-8、UTF-16、UTF-32
- UCS-2:早期 Unicode 编码方式,定长2字节,现已淘汰。【容易和UTF-16混淆】
- UTF-8:最流行的 Unicode 编码方式1~4个字节,与 ASCII兼容,适用于网络和跨平台文本处理。
- UTF-16:广泛用于操作系统和编程语言的内部表示,变长的编码方式,2个字节或4个字节。【既不和ASCII兼容,也不定长,集 UTF-8 和 UTF-32 缺点于一身??】
- UTF-32:定长,尽管和ASCII不兼容,但它编码简单
放个表:
| 年份 | 事件 |
|---|---|
| 1991 | UCS-2 发布:Unicode 1.0 中的编码方式,使用固定 2 字节表示字符,仅支持 BMP 范围(0x0000–0xFFFF)。 |
| 1992 | UTF-8 设计完成:由 Ken Thompson 和 Rob Pike 设计,作为一种变长编码方式,兼容 ASCII。 |
| 1993 | UTF-8 标准化:成为 Unicode 的正式编码方式(RFC 2279)。 |
| 1996 | UTF-16 发布:Unicode 2.0 推出,扩展编码范围至 0x0000–0x10FFFF,引入补充平面字符,支持代理对。 |
| 1996 | UCS-4 发布:ISO/IEC 10646 定义的 4 字节固定长度编码,支持完整 Unicode 范围。 |
| 1996 | UTF-7 标准化(RFC 1642):一种为电子邮件和其他 7 位传输协议设计的 Unicode 编码方式,但逐渐被废弃。 |
| 1999 | UTF-8 更新(RFC 3629):限制编码范围为 0x0000–0x10FFFF,与 Unicode 的定义保持一致。 |
| 2000s | UTF-8 成为主流:随着互联网的发展,UTF-8 被广泛应用于网页、协议(如 HTML、JSON)和操作系统中。 |
| 2000s | UTF-16 流行:Windows、Java、C# 等系统和语言内部采用 UTF-16 作为默认编码方式。 |
| 现代 | UCS-2 被淘汰:由于无法支持补充平面字符,UCS-2 被 UTF-16 完全取代。 |
| 现代 | UTF-32 用于内部处理:虽然内存占用高,但其编码简单,适用于数据库和编译器等场景。 |
附表
标准
- ISO/IEC 646
- ISO/IEC 8859
- ISO/IEC 2022
- ISO/IEC 10646
IANA 字符集注册表
IANA 字符集注册表(IANA Character Sets Registry) 是由 IANA(Internet Assigned Numbers Authority) 维护的一个标准化列表,用于记录和规范互联网上使用的 字符集(Character Sets)。该注册表为各种网络协议(如 HTTP、SMTP、MIME 等)提供了标准化的字符集名称、编号和相关信息,以确保跨平台、跨语言环境下的互操作性。
每个字符集分配一个唯一的 MIBenum 值,用于在 MIB(Management Information Base,管理信息库) 中标识字符集。范围划分:
- 0-2:保留。
- 3-999:由标准化组织分配的字符集。
- 1000-1999:Unicode 和 ISO/IEC 10646 编码。
- 2000 及以上:厂商特定字符集。
ANSI 编码
虽然名称中含有“ANSI”(American National Standards Institute,美国国家标准协会),但实际上它与 ANSI 标准没有直接关系,而是 Microsoft 自定义的字符集。
在 Windows 系统中,ANSI 编码实际上是基于 代码页(Code Page) 的单字节或多字节字符编码方案。每种语言或语言组在 Windows 中对应一个特定的代码页,ANSI 编码依赖这些代码页来表示特定语言的字符集。
一些常见的代码页:
| 代码页(Code Page) | 描述 | 语言/区域 | 对应的字符集 |
|---|---|---|---|
| 1250 | 中欧字符集 | 波兰语、捷克语、匈牙利语等 | Windows-1250 |
| 1251 | 西里尔字符集 | 俄语、乌克兰语、保加利亚语等 | Windows-1251 |
| 1252 | 西欧字符集(ANSI 默认) | 英语、法语、德语、西班牙语等 | Windows-1252 |
| 1253 | 希腊字符集 | 希腊语 | Windows-1253 |
| 1254 | 土耳其字符集 | 土耳其语 | Windows-1254 |
| 1255 | 希伯来字符集 | 希伯来语 | Windows-1255 |
| 1256 | 阿拉伯字符集 | 阿拉伯语 | Windows-1256 |
| 1257 | 波罗的海字符集 | 拉脱维亚语、立陶宛语等 | Windows-1257 |
| 1258 | 越南语字符集 | 越南语 | Windows-1258 |
| 936 | 简体中文字符集 | 简体中文 | GB2312(CP936) |
| 950 | 繁体中文字符集 | 繁体中文 | Big5(CP950) |
| 932 | 日文字符集 | 日语 | Shift_JIS(CP932) |
| 949 | 韩文字符集 | 韩语 | KS C 5601(CP949) |
Python内置编码的列表
作为参考,此处把Python手册中的编码表格列出来(注意,表格别名只列出部分名字)
| 编码名称 | 别名 | 语言 |
|---|---|---|
| ascii ★ | 646, us-ascii | 英语 |
| big5 | big5-tw, csbig5 | 繁体中文 |
| big5hkscs | big5-hkscs, hkscs | 繁体中文 |
| cp037 | IBM037, IBM039 | 英语 |
| cp273 | 273, IBM273, csIBM273 | 德语 |
| cp424 | EBCDIC-CP-HE, IBM424 | 希伯来语 |
| cp437 | 437, IBM437 | 英语 |
| cp500 | EBCDIC-CP-BE, EBCDIC-CP-CH, IBM500 | 西欧 |
| cp720 | - | 阿拉伯语 |
| cp737 | - | 希腊语 |
| cp775 | IBM775 | 波罗的海语言 |
| cp850 | 850, IBM850 | 西欧 |
| cp852 | 852, IBM852 | 中欧和东欧 |
| cp855 | 855, IBM855 | 保加利亚语、白俄罗斯语、马其顿语、俄语、塞尔维亚语 |
| cp856 | - | 希伯来语 |
| cp857 | 857, IBM857 | 土耳其语 |
| cp858 | 858, IBM858 | 西欧 |
| cp860 | 860, IBM860 | 葡萄牙语 |
| cp861 | 861, CP-IS, IBM861 | 冰岛语 |
| cp862 | 862, IBM862 | 希伯来语 |
| cp863 | 863, IBM863 | 加拿大法语 |
| cp864 | IBM864 | 阿拉伯语 |
| cp865 | 865, IBM865 | 丹麦语、挪威语 |
| cp866 | 866, IBM866 | 俄语 |
| cp869 | 869, CP-GR, IBM869 | 希腊语 |
| cp874 | - | 泰语 |
| cp875 | - | 希腊语 |
| cp932 | 932, ms932, mskanji, ms-kanji, windows-31j | 日语 |
| cp949 | 949, ms949, uhc | 韩语 |
| cp950 | 950, ms950 | 繁体中文 |
| cp1006 | - | 乌尔都语 |
| cp1026 | ibm1026 | 土耳其语 |
| cp1125 | 1125, ibm1125, cp866u, ruscii | 乌克兰语 |
| cp1140 | ibm1140 | 西欧 |
| cp1250 | windows-1250 | 中欧和东欧 |
| cp1251 | windows-1251 | 保加利亚语、白俄罗斯语、马其顿语、俄语、塞尔维亚语 |
| cp1252 | windows-1252 | 西欧 |
| cp1253 | windows-1253 | 希腊语 |
| cp1254 | windows-1254 | 土耳其语 |
| cp1255 | windows-1255 | 希伯来语 |
| cp1256 | windows-1256 | 阿拉伯语 |
| cp1257 | windows-1257 | 波罗的海语言 |
| cp1258 | windows-1258 | 越南语 |
| euc_jp | eucjp, ujis, u-jis | 日语 |
| euc_jis_2004 | jisx0213, eucjis2004 | 日语 |
| euc_jisx0213 | eucjisx0213 | 日语 |
| euc_kr | euckr, korean, ksc5601, ks_c-5601, ks_c-5601-1987, ksx1001, ks_x-1001 | 韩语 |
| gb2312 ★ | chinese, csiso58gb231280, euc-cn, euccn, eucgb2312-cn, gb2312-1980, gb2312-80, iso-ir-58 | 简体中文 |
| gbk ★ | 936, cp936, ms936 | 统一中文(Unified Chinese) |
| gb18030 ★ | gb18030-2000 | 统一中文(Unified Chinese) |
| hz | hzgb, hz-gb, hz-gb-2312 | 简体中文 |
| iso2022_jp | csiso2022jp, iso2022jp, iso-2022-jp | 日语 |
| iso2022_jp_1 | iso2022jp-1, iso-2022-jp-1 | 日语 |
| iso2022_jp_2 | iso2022jp-2, iso-2022-jp-2 | 日语、韩语、简体中文、西欧、希腊语 |
| iso2022_jp_2004 | iso2022jp-2004, iso-2022-jp-2004 | 日语 |
| iso2022_jp_3 | iso2022jp-3, iso-2022-jp-3 | 日语 |
| iso2022_jp_ext | iso2022jp-ext, iso-2022-jp-ext | 日语 |
| iso2022_kr | csiso2022kr, iso2022kr, iso-2022-kr | 韩语 |
| latin_1 ★ | iso-8859-1, iso8859-1, 8859, cp819, latin, latin1, L1 | 西欧 |
| iso8859_2 | iso-8859-2, latin2, L2 | 中欧和东欧 |
| iso8859_3 | iso-8859-3, latin3, L3 | 世界语、马耳他语 |
| iso8859_4 | iso-8859-4, latin4, L4 | 波罗的海语言 |
| iso8859_5 | iso-8859-5, cyrillic | 保加利亚语、白俄罗斯语、马其顿语、俄语、塞尔维亚语 |
| iso8859_6 | iso-8859-6, arabic | 阿拉伯语 |
| iso8859_7 | iso-8859-7, greek, greek8 | 希腊语 |
| iso8859_8 | iso-8859-8, hebrew | 希伯来语 |
| iso8859_9 | iso-8859-9, latin5, L5 | 土耳其语 |
| iso8859_10 | iso-8859-10, latin6, L6 | 北欧语言 |
| iso8859_11 | iso-8859-11, thai | 泰语 |
| iso8859_13 | iso-8859-13, latin7, L7 | 波罗的海语言 |
| iso8859_14 | iso-8859-14, latin8, L8 | 凯尔特语言 |
| iso8859_15 | iso-8859-15, latin9, L9 | 西欧 |
| iso8859_16 | iso-8859-16, latin10, L10 | 东南欧语言 |
| johab | cp1361, ms1361 | 韩语 |
| koi8_r | - | 俄语 |
| koi8_t | - | 塔吉克语 |
| koi8_u | - | 乌克兰语 |
| kz1048 | kz_1048, strk1048_2002, rk1048 | 哈萨克语 |
| mac_cyrillic | maccyrillic | 保加利亚语、白俄罗斯语、马其顿语、俄语、塞尔维亚语 |
| mac_greek | macgreek | 希腊语 |
| mac_iceland | maciceland | 冰岛语 |
| mac_latin2 | maclatin2, maccentraleurope, mac_centeuro | 中欧和东欧 |
| mac_roman | macroman, macintosh | 西欧 |
| mac_turkish | macturkish | 土耳其语 |
| ptcp154 | csptcp154, pt154, cp154, cyrillic-asian | 哈萨克语 |
| shift_jis | csshiftjis, shiftjis, sjis, s_jis | 日语 |
| shift_jis_2004 | shiftjis2004, sjis_2004, sjis2004 | 日语 |
| shift_jisx0213 | shiftjisx0213, sjisx0213, s_jisx0213 | 日语 |
| utf_32 ★ | U32, utf32 | 所有语言 |
| utf_32_be | UTF-32BE | 所有语言 |
| utf_32_le | UTF-32LE | 所有语言 |
| utf_16 ★ | U16, utf16 | 所有语言 |
| utf_16_be | UTF-16BE | 所有语言 |
| utf_16_le | UTF-16LE | 所有语言 |
| utf_7 | U7, unicode-1-1-utf-7 | 所有语言 |
| utf_8 ★ | U8, UTF, utf8, cp65001 | 所有语言 |
| utf_8_sig | - | 所有语言 |
Qt支持的编码
在Qt6,QStringConverter 支持如下编码:
- UTF-8
- UTF-16
- UTF-16BE
- UTF-16LE
- UTF-32
- UTF-32BE
- UTF-32LE
- ISO-8859-1 (Latin-1)
- The system encoding
Qt 的 QTextCodec 支持如下的编码(注:Qt6中QTextCodec已经被边缘化了):
- Big5
- Big5-HKSCS
- CP949
- EUC-JP
- EUC-KR
- GB18030
- HP-ROMAN8
- IBM 850
- IBM 866
- IBM 874
- ISO 2022-JP
- ISO 8859-1 to 10
- ISO 8859-13 to 16
- Iscii-Bng, Dev, Gjr, Knd, Mlm, Ori, Pnj, Tlg, and Tml
- KOI8-R
- KOI8-U
- Macintosh
- Shift-JIS
- TIS-620
- TSCII
- UTF-8
- UTF-16
- UTF-16BE
- UTF-16LE
- UTF-32
- UTF-32BE
- UTF-32LE
- Windows-1250 to 1258
参考
- https://docs.python.org/3/library/codecs.html#standard-encodings
- https://en.wikipedia.org/wiki/EBCDIC
- https://en.wikipedia.org/wiki/ASCII
- https://en.wikipedia.org/wiki/Extended_ASCII
- https://en.wikipedia.org/wiki/GBK_(character_encoding)
- https://en.wikipedia.org/wiki/GB_2312
- https://en.wikipedia.org/wiki/Big5
- https://en.wikipedia.org/wiki/Unicode
- https://en.wikipedia.org/wiki/ISO/IEC_646
- https://en.wikipedia.org/wiki/ISO/IEC_10646
- https://en.wikipedia.org/wiki/ISO/IEC_2022
- https://en.wikipedia.org/wiki/Extended_Unix_Code
- https://www.iana.org/assignments/character-sets/character-sets.xml